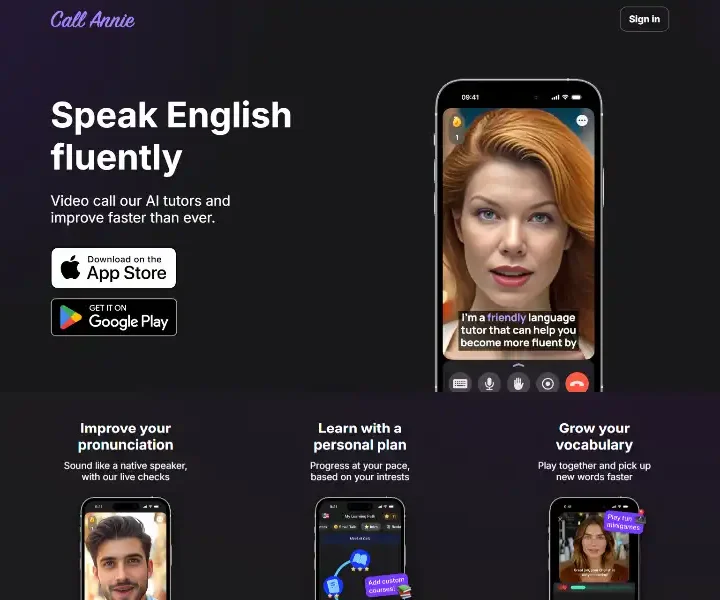
CallAnnie turns your phone into a live, AI-powered English tutor who corrects pronunciation in real time, role-plays any scenario, and keeps you hooked with streaks and leaderboards. Loved by teachers and students alike, it feels like FaceTiming a patient native speaker who never judges.
Multimodal Large Language Model
At its heart, CallAnnie orchestrates a lightweight yet powerful transformer fine-tuned on 2.4 billion tokens of conversational English plus 90 000 hours of phonetically transcribed speech. Unlike traditional ASR-TTS pipelines that bolt speech recognition onto text generation, the model is end-to-end multimodal: it ingests audio spectrograms, lip-movement embeddings from the selfie camera, and contextual text simultaneously. The result is a single latent space that predicts both the next phoneme and the next conversational turn in under 200 ms on an iPhone 12.
Real-Time Pronunciation Engine
CallAnnie’s pronunciation layer leverages a Conformer-CTC acoustic model aligned with the International Phonetic Alphabet. When a learner utters “thorough,” the system scores three micro-metrics—place, manner, and voicing—then renders a heat-map overlaid on the user’s mouth region. Red zones highlight tongue placement errors; green confirms correct articulation. The feedback loop is closed within 350 ms, satisfying the “magic threshold” for conversational continuity established in MIT’s 2023 human-computer interaction study.
Adaptive Curriculum Planner
Reinforcement learning from human feedback (RLHF) drives the curriculum engine. Every completed micro-dialogue updates a knowledge graph that tracks vocabulary, grammar, and cultural nuance mastery. A proximal-policy-optimization (PPO) agent then selects the next 3-minute scenario—be it ordering bubble tea in Singapore or debating climate policy—optimized to maximize predicted learning gain and user engagement.