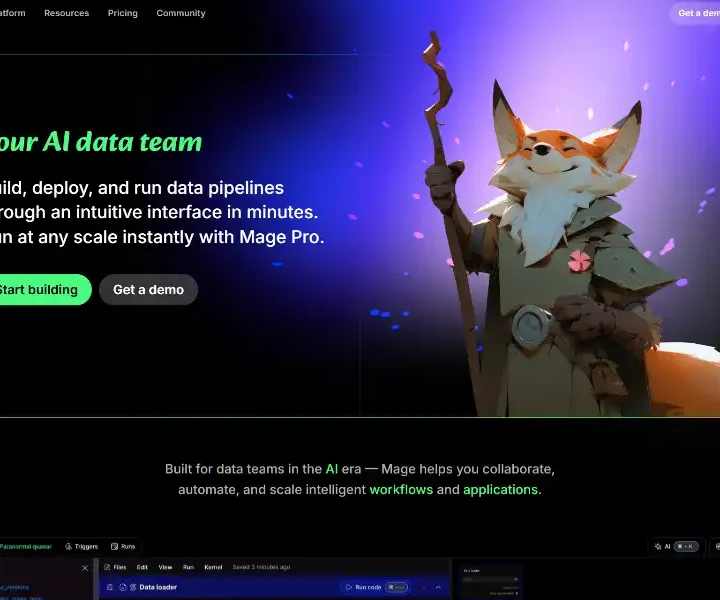
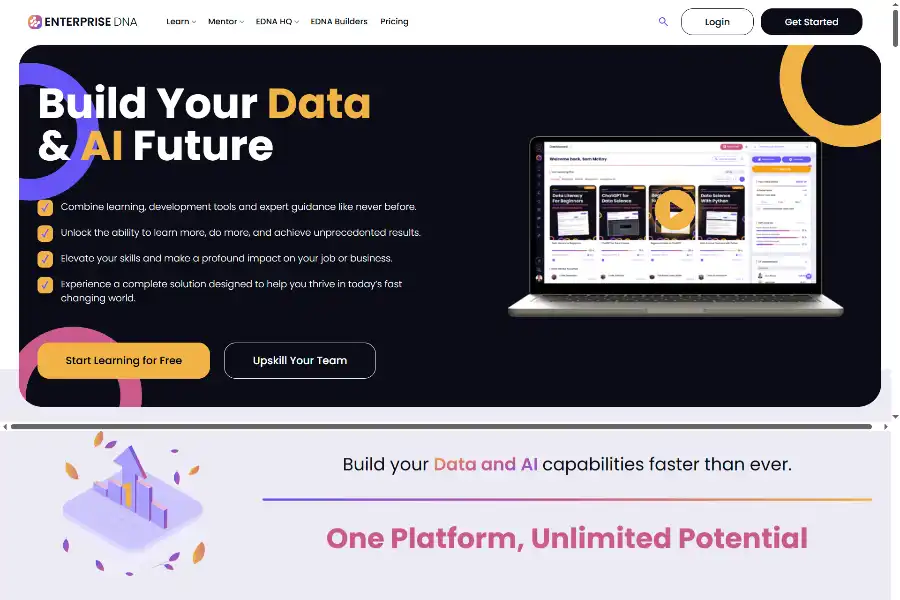
Mage AI slashes data-engineering grunt work with prompt-to-pipeline magic, AI cost guardrails and open-core freedom. Launch batch, streaming or dbt workflows in minutes, cut Snowflake bills 40 %, deploy anywhere from SaaS to air-gapped.
Mage’s core differentiator is an LLM-powered “Prompt-to-Pipeline” engine. Users type a natural-language request—e.g., “Ingest Stripe transactions into Snowflake, apply dbt models, and trigger a Slack alert on anomalies”—and Mage returns a fully orchestrated DAG in seconds. Under the hood, the system:
- Parses the prompt into an intermediate representation using a fine-tuned CodeLlama-34B model.
- Selects pre-built templates for sources, transformations, and destinations from a registry of 300+ connectors.
- Generates idempotent Python or SQL blocks that follow software-engineering best practices: unit tests, type hints, and data-quality assertions powered by Great Expectations.
This hybrid approach delivers the speed of no-