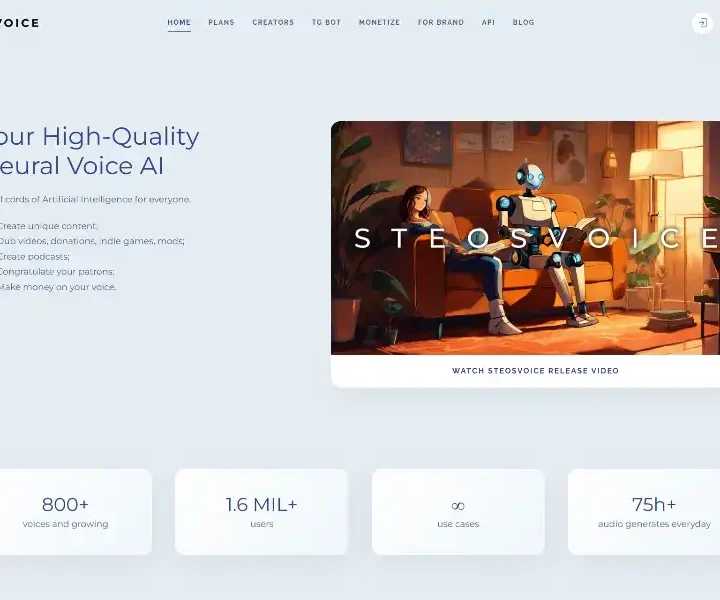
SteosVoice is the AI voice powerhouse that turns any text into studio-grade, emotionally rich speech in 42 languages. Clone your own voice with 30 seconds of audio, access 1,000+ character voices, and dub videos, games, or podcasts in minutes. Loved by 4.8/5-rated creators for its real-time speed and GDPR-compliant security, it slashes production costs by up to 90 %.
SteosVoice is built on a proprietary stack that merges state-of-the-art neural TTS (text-to-speech) with zero-shot voice cloning and prosody transfer.
- Neural TTS Backbone: A Transformer-based acoustic model converts graphemes into mel-spectrograms, while a HiFi-GAN vocoder upsamples the spectrograms into 48 kHz waveforms. The result is CD-quality audio without the metallic artifacts typical of older engines.
- Zero-Shot Voice Cloning: With only 5–30 seconds of clean reference audio, the system extracts a speaker embedding vector using a contrastive pre-training objective. This vector conditions the TTS decoder so the synthetic voice retains the timbre, pitch envelope, and breathing patterns of the original speaker—even in languages the reference speaker never uttered.
- Prosody Transfer & Emotion Tags: Users can append emotional descriptors such as excited, whisper, or sarcastic in SSML-like tags. A prosody predictor network trained on 4,000 hours of multilingual drama corpora adjusts energy, pause, and intonation curves, producing performances that rival human voice actors.
- Real-Time Streaming: An optimized inference engine based on NVIDIA TensorRT delivers sub-300 ms latency on a single GPU, enabling live voice donations on Twitch or real-time dubbing during gameplay.